故事是這樣子的,最近小弟在看 github 上一個 os 的教學
,跟 jserv 大大的 mini-arm-os
有點像,
都是教你從頭幹一個作業系統出來,只不過這個是幹在 X86 處理器上,某種程度上我覺得在 X86 上寫開機程式根本是各種考古,還要從 real mode 一路開上來(yay
最近剛寫好小弟第一個 X86 kernel ,結果因為在 link kernel 的時候,object 檔案的順序寫錯,害我 de 了一輪搖曳露營 OST 的 bug,超白痴。
扯遠了,其實這篇是要講 wiki 的,在寫作業系統的時候不免會去查一些 wiki 資料,然後就發現某些條目充滿了中國風格的用語,當然上面選擇台灣正體也不是看不懂但就是煩,於是把過去註冊密碼忘了的 wiki 帳號找了回來,自己來做個編輯,這裡記錄一下流程,希望大家有看到類似的狀況也可以順手修正一下。
我看到的文章是這篇:X86 呼叫慣例
參考用的資料:wiki 繁簡處理說明
首先先打開上例的 X86 呼叫慣例的頁面,會發現網址的部分,其實是 zh-tw/X86调用约定,這是因為 wiki 的規定是所有的中文頁面都是同樣的內容,
再用之後會提到的轉換方式,轉換為中國(zh-cn)、新加坡(zh-sg)及馬來西亞(zh-my)三種簡體中文;
台灣(zh-tw)、香港(zh-hk)和澳門(zh-mo)三個繁體中文。
所以在條目上變成先佔先贏,也就是有了「X86调用约定」的頁面的話,就不能新建「X86呼叫約定」的條目,必須只能編輯這個頁面,請見繁簡轉換的條目標題
。
然後編輯內容也不能隨意將簡體轉成繁體或反向轉換,否則會被視為破壞;
另外文中的異體字、日本漢字也都有自己的處理方式,不過這裡我們今天不會提到。
這麼做的好處,就是無論簡體或繁體都會貢獻中文的所有頁面,壞處就是用語、行文等習慣,會需要花費時間轉換, 而且我很懷疑能不能轉得好,像是文字轉過去了文法卻沒法用轉換的,對編輯者來說也很麻煩,像我如果要編輯簡體先到先得的頁面,就得要用簡體編輯才行,我個人是覺得壞處是大過好處的… 但總之這是現下 wiki 的政策,再怎麼智障也只能先遵循(我其實找不太到這個政策形成的過程,也許有知道的人可以補個脈絡)。
再來就要到所謂地區詞處理了,請見wiki 地區詞處理說明 : 例如 stack 繁體為堆疊,中國簡體則是堆栈或栈,現下 wiki 的做法就是本文一律先到先得,編輯者是簡體中文就寫簡體中文,讀者選擇台灣正體的時候,再轉換成繁體頁面。
這裡的系統畫成階層圖大概是這樣:
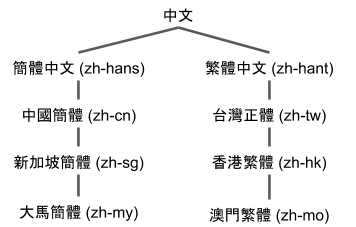
愈下面的地區碼針對性就愈強,指定 zh-mo 就只會在澳門繁體頁面才會轉換,但指定繁體中文就會在下面三個語言都轉換; 另外 wiki 有幾個不同階層的轉換:由上而下為
- 全域轉換
全域轉換就是超暴力所有 wiki 範圍內的文字都轉換,誤殺率很高,只有非常針對絕對不會誤殺的詞才能進去,例如台灣正體轉換表的:米芝蓮=>米其林。 - 全文轉換
全文轉換雷同,只是在一篇文章內通殺。 - 公共組轉換
公共轉換組應該是最實用的,也就是針對資訊科技,定義好一系列的對照表,這些對照表就能套用到跟資訊科技相關的文章中。 - 單獨轉換
單獨轉換就是用來針對固定位置的詞來做轉換
我在看到 X86调用约定的時候,就是因為沒上資訊科技的IT 公共轉換組
。
以致雖然是繁體頁面內容卻都是中國用語(例如標題轉換成 X86調用約定),修正方式也很簡單,在原始碼的部分加上 NoteTA 的轉換模版
就好:
{{noteTA
|T=zh-hans:X86调用约定; zh-hant:X86呼叫慣例;
|G1=IT
}}
其中 T 表示標題的轉換
G1~Gn 則是引用公共轉換組,這裡引用一個 IT 的,至於你說為什麼我知道要引用這個…呃…目前我只知道從類似條目去找,
或者從全部的列表
裡去找(yay
其實只要加上公共轉換組,看起來就會順眼很多了,自然會有一些詞沒修正到,只能之後手動下去修,像公共轉換組只定義堆栈要轉成堆疊,但原始碼有人只寫栈就轉不過去了。
大概就是這樣,要讓 wiki 用詞跟習慣一樣,還是需要大大們多多動手做點小修改,
我個人還是覺得把簡體跟繁體頁面合併滿白痴的,你看我們定義了這麼多的公共轉換組,其實連個 X86呼叫慣例都轉換不好,
說到底簡體中文跟繁體中文已經不是文字上的差別,而是連文法上都有差異了吧