終於來到我隱藏已久的終極目標了。
沒錯,其實我在拿到這片 FPGA,在想要做什麼的時候,經過一天得到的答案就是這個:Nand2Tetris
,
用 FPGA 真的把這顆 CPU 給做出來,前面什麼 UART、HDMI、BRAM 都不過是前菜罷了,實際上我在下很大一盤棋。
當然,因為我們用的是 verilog 的關係,我們不會真的從 nand gate 開始往上堆,而是用 verilog 內建的運算來實作,
所以 nand2tetris 第一、二章用 nand 弄出邏輯閘和加法器的部分就跳過,直接從 ALU 開始。
CPU
ALU
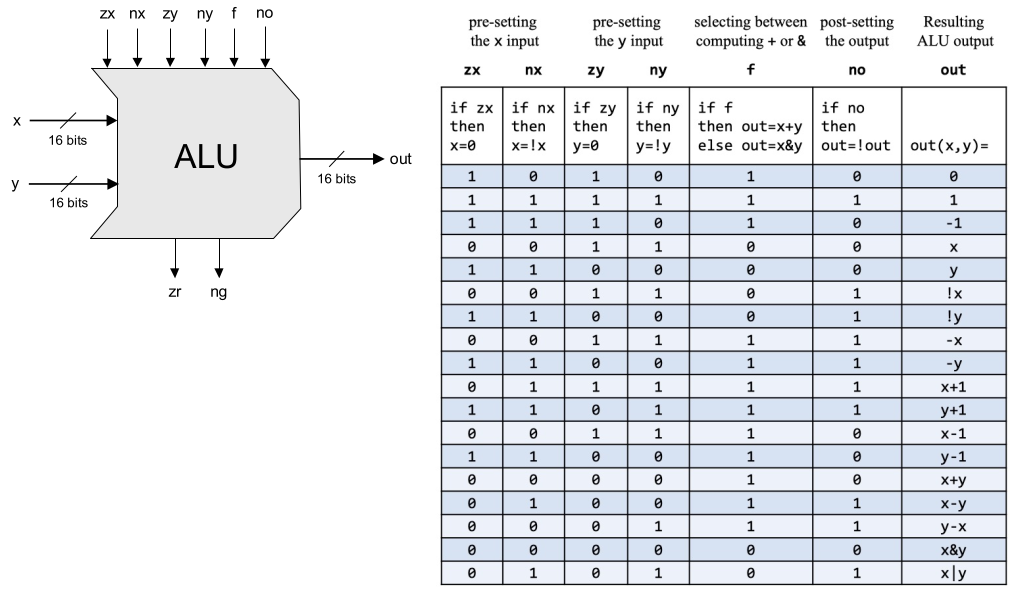
上圖是 Nand2Tetris 的 ALU 設計,六根控制信號 zx, nx, zy, ny, f, no,分別表示:
- zx:選擇 input 1 或 0 作為 x
- nx:not x
- zy:選擇 input2 或 0 作為 y
- ny:not y
- f:out = x+y 或 x&y
- no:not out
兩根輸出 flag 表示輸出是否為 0 或是否是負值;這完全是 combinational circuit 的組合,實作也非常簡單,最難的可能是在接線的命名:
module hack_alu (
input i_zx,
input i_nx,
input i_zy,
input i_ny,
input i_f,
input i_no,
input [15:0] inx,
input [15:0] iny,
output logic o_zero,
output logic o_negative,
output logic [15:0] out
);
logic [15:0] zerox;
logic [15:0] notx;
logic [15:0] zeroy;
logic [15:0] noty;
logic [15:0] fout;
assign zerox = i_zx ? 0 : inx;
assign notx = i_nx ? ~zerox : zerox;
assign zeroy = i_zy ? 0 : iny;
assign noty = i_ny ? ~zeroy : zeroy;
assign fout = i_f ? notx + noty : notx & noty;
assign out = i_no ? ~fout : fout;
assign o_zero = out == 0;
assign o_negative = out[15] == 1;
endmodule
沒錯這樣就實作完了。
Register 和 PC
register 跟 pc 是 sequential 的元件,會在 clk 來的時候把 input 值存入 flip-flop:
module hack_pc (
input clk,
input rst,
input inc,
input load,
input [15:0] in,
output logic [15:0] out
);
always_ff @(posedge clk or negedge rst) begin
if (!rst) begin
out <= 0;
end
else if (load) begin
out <= in;
end
else if (inc) begin
out <= out + 1;
end
end
endmodule
只要把 inc 這條線拿掉,就會從 pc 變成 register 了。
module register (
input clk,
input [15:0] in,
input load,
output logic [15:0] out
);
always_ff @(posedge clk) begin
if (load) begin
out <= in;
end
end
endmodule
CPU
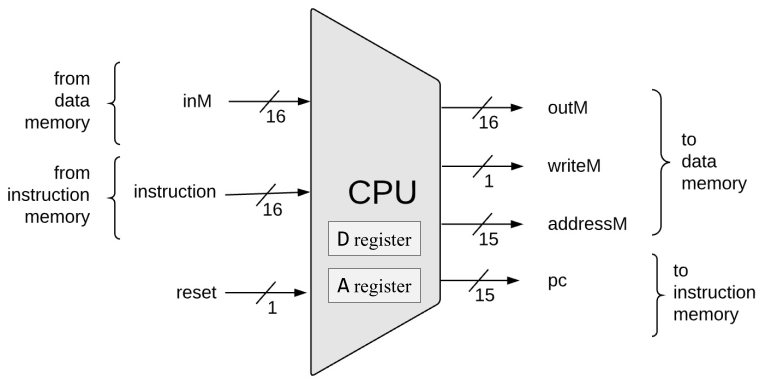
Nand2Tetris CPU 的介面如下:
- rst:重設 CPU
- instruction:來自 ROM 的 instruction
- inM:從 RAM 讀取指定記憶體位址的內容
- outM/addressM/writeM:寫入 RAM 的內容、位址、是否寫入
- pc:下一個從 ROM 中取 instruction 的位址
這個介面可以很簡單的轉成 verilog 實作:
module hack_cpu (
input clk,
input rst,
input [15:0] instruction,
input [15:0] i_memory,
output logic o_we,
output logic [15:0] o_out,
output logic [15:0] o_addr,
output logic [15:0] o_pc
);
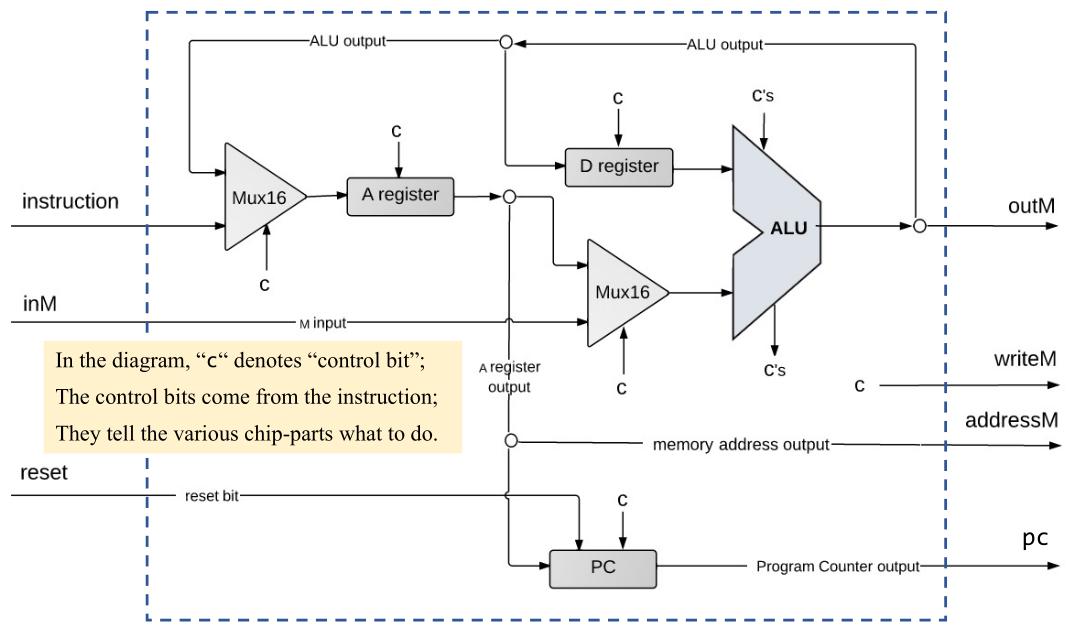 Hack CPU 的架構圖如上,裡面有兩個 register,D (Data) Register 跟 A (Address) Register;
顧名思義,A register 的值表示的就是現在要存取 Memory 的位址;D Register 則是運算用的資料。
Hack CPU 的架構圖如上,裡面有兩個 register,D (Data) Register 跟 A (Address) Register;
顧名思義,A register 的值表示的就是現在要存取 Memory 的位址;D Register 則是運算用的資料。
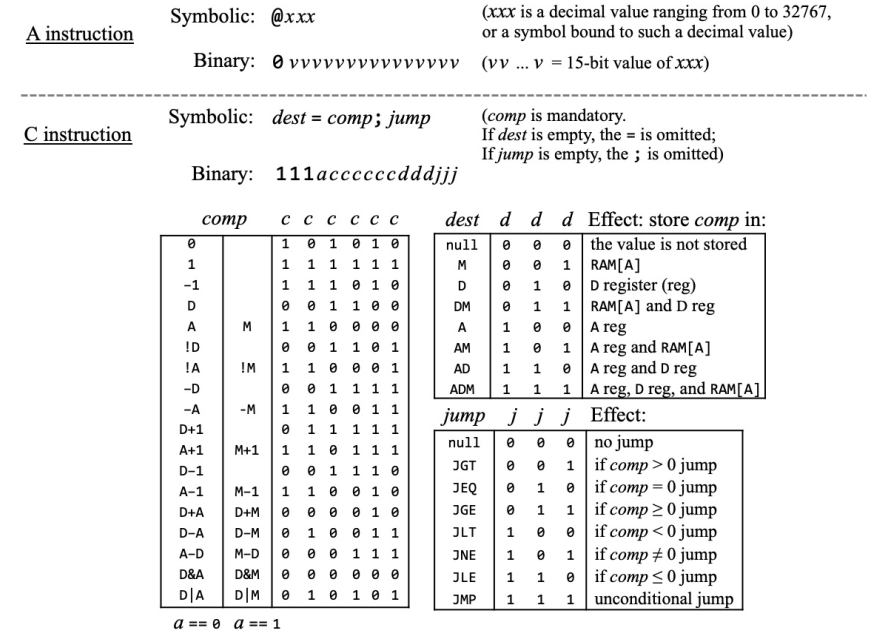
Hack CPU 只有兩種指令:
- A instruction,開頭為 0 表示,把後面的 15 bits 的數值存入 A register。
- C instruction,開頭為 1,後面幾個 bits 分別代表:
- a:選擇 ALU 的輸入是 A register 或 memory input。
- c:決定 ALU 要進行的運算。
- d:Destnation,運算結果要是否要寫入 A register/D register/RAM 裡面。
- j:Jump,依運算結果是否進行跳轉。
內部的實作如圖所示,要做的其實就是把線接一接就可以了,實作如下:
logic [15:0] inx;
logic [15:0] iny;
logic [15:0] addr_instruction;
logic [15:0] a_out;
logic [15:0] alu_out;
logic [15:0] next_pc;
logic f_zero;
logic f_negative;
logic jump;
logic is_A_inst, is_C_inst;
assign is_A_inst = (instruction[15] == 0);
assign is_C_inst = !is_A_inst;
assign addr_instruction = is_A_inst ? instruction : alu_out;
assign iny = instruction[12] ? i_memory : a_out;
always_comb begin
if (is_C_inst) begin
case ({instruction[2], instruction[1], instruction[0]})
3'b000: jump = 0;
3'b001: jump = !(f_negative || f_zero);
3'b010: jump = f_zero;
3'b011: jump = !f_negative;
3'b100: jump = f_negative;
3'b101: jump = !f_zero;
3'b110: jump = f_negative || f_zero;
3'b111: jump = 1;
endcase
end
else begin
jump = 0;
end
end
上面這段先把一些線宣告一下,兩個 assign 的三元運算就對應到圖中的兩個 mux;jump 信號的實作也不用像 nand2tetris 實作, 在那邊畫 karnaugh map 化約成邏輯閘, 我們在 verilog 不來這套,讓 synthesizer 去煩惱就好了。
hack_pc pc (
.clk(clk), .rst(rst),
.inc(1'b1), .load(jump),
.in(a_out + 1), .out(next_pc)
);
register register_d (
.clk(clk),
.in(alu_out),
.load(is_C_inst && instruction[4]),
.out(inx)
);
register register_a (
.clk(clk),
.in(addr_instruction),
.load(instruction[5] || is_A_inst),
.out(a_out)
);
hack_alu alu (
.i_zx(instruction[11]),
.i_nx(instruction[10]),
.i_zy(instruction[9]),
.i_ny(instruction[8]),
.i_f(instruction[7]),
.i_no(instruction[6]),
.inx(inx),
.iny(iny),
.o_zero(f_zero),
.o_negative(f_negative),
.out(alu_out)
);
assign o_out = alu_out;
assign o_addr = a_out;
assign o_we = !is_A_inst && instruction[3];
assign o_pc = jump ? a_out : next_pc;
這段就是用線把幾個元件接一接,CPU 就完成啦。 我的 CPU 設計上,o_pc 和 pc module 的 in 有一些修改,這個跟後面接 ROM 的部分有關,稍後會提到。
Memory
Memory 應該是本次最大的麻煩,nand2tetris 在設計上,每個位址有 16 bits 的資料:
- ROM 定址 32 K
- RAM 定址 16 K
- display memory 定址 8 K
- 1 byte 的鍵盤輸入,這個我們先不管它
如上一篇 block memory 所提,我們有 56 個 DP16KD,設定為 16 bits 的資料寬度時,每個 DP16KD 可以存 1K 個條目,所以我們只有 56 K 條定址。
理論上 56 = 32 + 16 + 8,但是我們在這裡遇到一個大麻煩,依照 DP16KD 的文件,它應該是一個 True Dual Port 的記憶體單元,
也就是說支援兩組輸入輸出,可以走不同的 clock、位址、資料,但問題就在: yosys 不吃這套死廢物耶。
我實作了 dual port 的 block memory,在 yosys 合成的時候它無法把 DP16KD 放上去, 這是 yosys 的記憶體模型一個長期以來的 bug , 也有其他人報過類似的 issue ,雖然 issue 2020/04 就開了, 不過還無法預期什麼時候可能修好,這在 open source 界也是很常有的事。
那放不上 Dual Port memory 會怎麼樣呢?
答案是 yosys 會把 Dual Port 的部分用兩個 single port 來取代,然後用個奇怪的方法讓兩邊同步。
唯一需要 dual port 的元件就是 display memory,要讓 CPU 跟 HDMI 分頭存取,
因此它需要兩倍也就是 16K 定址,這樣子 block memory 就不夠用了。
我使用最簡的解法,先把 ROM 調小,目前設計是:
- ROM 定址 16K
- RAM 定址 16K
- display memory 定址 8K + 8K 總共 48 K。
ROM
下面就來實作 ROM,中間這段 `ifdef 是為了搭配 verilator 作驗證,因為 verilator 不接受 if (FILE) 這樣的寫法,只能用 ifdef 將它隔開;
在 ROM 使用 readmemb 將 nand2tetris 的 code 載入 ROM 裡面,就如上一章載入圖片資料一樣。
module rom (
input clk,
input [DEPTH-1:0] addr,
output logic [WIDTH-1:0] data
);
parameter WIDTH=16;
parameter DEPTH=14;
parameter SIZE=(1<<DEPTH);
parameter FILE="rom.hack";
logic [WIDTH-1:0] ram [0:SIZE-1];
`ifdef verilator
initial begin
$readmemb("rom.hack", ram);
end
`else
initial begin
if (FILE) begin
$readmemb(FILE, ram);
end
end
`endif
always_ff @(posedge clk) begin
data <= ram[addr];
end
endmodule
因為 ROM 也是有敲 clock 的,也就是說位址準備好之後,一個 clock 之後才會輸出資料,這在本來 nand2tetris 設計上會變成 bubble。
畫成表,時序由上而下大概是這樣:
| Instruction, ROM output | next PC | PC output |
|---|---|---|
| n, jump to k | k | n+1 |
| n+1 | k+1 | k |
| k | k+2 | k+1 |
可以看到多執行了一個不該執行的 n+1 指令;因為 next instruction 都要在 PC 敲一次 clock,在 ROM 又敲一次 clock;
一個解法當然是把上面的 ROM 改成 combinational circuit,但我不確定這樣能不能正常合成出 block memory。
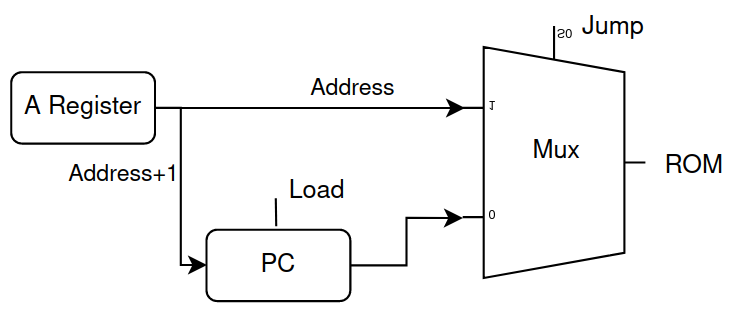
因此我在 CPU 對 PC 的輸出入做了修改,改成如下圖所示
的樣子,
在要 jump 的時候不會先把 jump address 送進 PC,
而是透過 mux 直接送給 ROM,改將 jump address +1 送到 PC,這樣跳轉一結束就會繼續執行跳轉後的下一個指令。
RAM
RAM 就沒什麼特別的了,宣告 16K 的 ram 和 8K 的 screen,CPU 的存取會分別導向這兩塊 memory;GPU 則只存取 screen。
module ram (
input clk,
// CPU rw side
input we,
input [DEPTH-1:0] addr,
output logic [WIDTH-1:0] data_rd,
input [WIDTH-1:0] data_wr,
input [DEPTH-1:0] gpu_addr,
output logic [WIDTH-1:0] gpu_data
);
localparam WIDTH = 16;
localparam DEPTH = 16;
localparam RAM_SIZE = (1<<14);
localparam SCREEN_SIZE = (1<<13);
// 16K cpu ram
logic [WIDTH-1:0] ram [0:RAM_SIZE-1];
// 8K screen ram
logic [WIDTH-1:0] screen [0:SCREEN_SIZE-1];
logic [WIDTH-1:0] ram_data;
logic [WIDTH-1:0] screen_data;
// CPU side
always_comb begin
ram_data = ram[addr[13:0]];
end
always_ff @(posedge clk) begin
if (we && addr[15:14] == 2'b00) begin
ram[addr[13:0]] <= data_wr;
end
end
always_comb begin
screen_data = screen[addr[12:0]];
end
always_ff @(posedge clk) begin
if (we && addr[15:14] == 2'b01) begin
screen[addr[12:0]] <= data_wr;
end
end
always_comb begin
if (addr[15:14] == 2'b00) begin
data_rd = ram_data;
end
else if (addr[15:14] == 2'b01) begin
data_rd = screen_data;
end
else begin
data_rd = 0;
end
end
// GPU side
always_ff @(posedge clk) begin
gpu_data <= screen[gpu_addr[12:0]];
end
endmodule
top module
整個模組的基底就是上次播放乃哥黃金開口笑的模組。
logic [15:0] rom_addr;
logic [15:0] instruction;
logic [15:0] mem_out;
logic mem_we;
logic [15:0] cpu_out, addr;
logic [15:0] gpu_addr, gpu_data;
rom #(
.WIDTH(16),
.DEPTH(14),
.SIZE(1<<14),
.FILE("rom.hack")
) rom_i (
.clk(clk),
.addr(rom_addr[13:0]), .data(instruction)
);
hack_cpu cpu (
.clk(clk), .rst(rst),
.instruction(instruction), .i_memory(mem_out),
.o_we(mem_we), .o_out(cpu_out),
.o_addr(addr), .o_pc(rom_addr)
);
ram ram_i (
.clk(clk),
.we(mem_we),
.addr(addr), .data_rd(mem_out), .data_wr(cpu_out),
.gpu_addr(gpu_addr), .gpu_data(gpu_data)
);
這段把模組間的線接一接,上面的 gpu_addr 和 gpu_data 來自於上一輪的 imagesrc, 本來是用 counterX/counterY 拿到對應位置、尺寸為 1 個 byte 的 pixel 資料。
Nand2Tetris 一個 pixel 就是一個 bit,螢幕尺寸為 512x256,總共有 131072 pixel 也就是 RAM 定址 8K x 每個位址 16 bits 的內容。
這裡會使用 counterX/counterY ,計算要拿出哪個 address 裡的 16 bits 資料,並顯示該 pixel全白或全黑,address, data 和 pixel 間的計算如下:
assign gpu_addr = (counterY << 5) + (counterX >> 4);
always_comb begin
if (counterX >= 512 || counterY >= 256) begin
pixel = 24'd0;
end
else begin
pixel = (gpu_data[counterX & 4'hf]) ? 24'hffffff : 0;
end
end
除錯
我們準備好我們的 CPU 之後,程式碼會由 rom.hack 這個檔案寫入 ROM 裡面,一上電就會從位址 0 的部分開始執行。
一開始我先使用 RectL.asm
來做測試,
應該要在螢幕左上角畫一個小正方式, 結果出了一些問題,
搭配 verilator 除錯之後,竟然在我之前自幹的 assembler 裡面找到兩個 bug:
- 第一個是沒考慮到 leading/trailing space 造成 jump 字串的判斷錯誤,asm 寫 jump 結果沒有 jump。
- 另一個是沒處理 A+D 跟 D+A、D+M 跟 M+D 的差別,一樣吐了錯誤的 command 出來。
找到 bug 的時候差點笑死。
執行
我測試的程式碼如下:
Sys.jack
class Sys {
/** Performs all the initializations required by the OS. */
function void init() {
do Screen.init();
do Main.main();
do halt();
}
/** Halts execution. */
function void halt() {
while (true) {
}
}
function void oneMilliSecond() {
var int i;
let i = 0;
while (i < 275) {
let i = i + 1;
}
return;
}
function void wait(int duration) {
var int i;
let i = 0;
while (i < duration) {
do oneMilliSecond();
let i = i + 1;
}
return;
}
}
Sys 提供了 oneMilliSecond 函式和 wait 函式,oneMilliSecond 的 275 是實驗出來的,理論上可以去查找 assembly, 看看這個 while loop 會執行多少個指令,然後去算執行 25000 個指令要執行多少次迴圈,不過我懶…畢竟我自己寫的編譯器編出來的 code 沒人看得懂…。
Screen.jack
class Screen {
static array SCREEN;
static int SCRSIZ;
static boolean COLOR;
/** Initializes the Screen. */
function void init() {
let SCREEN = 16384;
let SCRSIZ = 8192;
let COLOR = true;
return;
}
function void fillScreen(bool on) {
var int i;
let i = 0;
while(i < SCRSIZ) {
let SCREEN[i] = on;
let i = i + 1;
}
return;
}
}
Screen 本來會提供更多必要的繪圖函式,刪掉只留下 fillScreen 把整個全螢幕變黑或變白,作為測試之用。
Main.jack
class Main {
function void main() {
while(true) {
do Screen.fillScreen(true);
do Sys.wait(1000);
do Screen.fillScreen(false);
do Sys.wait(1000);
}
return;
}
}
Main 函式就是不斷的變白變黑。
整個編譯流程使用我自己實作的工具
來編譯,
包括 JackCompiler 從 Jack 編譯成 .vm 檔;VMTranslator 由 .vm 檔編譯成 assembly;
最後是 Rust 實作的 HackAssembler 直譯為 Nand2Tetris 的 binary;輸出 binary 就是可以直接用 readmemb 寫入 ROM 的格式了。
這是執行時的影片:
nand2tetris 範例
nand2tetris 內部有三個範例程式
- Screen
- Output
- String
最後測試的結果,只有 Screen Test 能夠成功跑起來,其他兩個測試尺寸分別來到 34K 跟 26K ,都超過我們 ROM 能容納的大小。
發文的時候,上面影片放的是我把畫面弄黑弄白的畫面,原因其實是我硬體設計有 bug,導致 nand2tetris 課程提供測試畫面會有破損, 經過這一個星期,透過 verilator 倒波形出來, 在強者我同事 phoning 的幫助之下,陸續解掉兩個不同的 bug。
phoning:沒有看波形解不掉的問題,如果…沒有如果!沒有就是沒有!
那為什麼我要在還沒完全把 bug 修掉的時候就把文章貼出來?啊就捏不住啊,以為寫出一個 CPU 有多了不起。
首先第一個 bug 是我在 ram 那邊,讀 screen 裡面的 data 寫成敲 clock 的,CPU 讀取 screen data 的時候晚了一個 cycle,
因此每次 CPU 要寫入 screen 的時候,都讀不到之前已經寫入 screen 的資料,會把它覆寫過去。
這在把畫面整個變白變黑的時候沒差,因為每個資料都是寫全 1 全 0 進去;但改用 nand2tetris 的 Screen API 時,
它是一個一個像素畫上去的,就會變成畫一條線,每 16 bits 只有最後寫入的 bit 畫上去。
第二個問題也是跟 cycle 有關,在 ram 裡面讀取的部分我們是這樣寫:
// CPU side
always_comb begin
ram_data = ram[addr[13:0]];
end
// 第一個問題就是 screen_data 這裡寫錯,寫成 always_ff 資料就慢了一個 cycle
always_comb begin
screen_data = screen[addr[12:0]];
end
// GPU side
always_ff @(posedge clk) begin
gpu_data <= screen[gpu_addr[12:0]];
end
好的,所以 gpu 這邊從 ram 裡面拿資料的時候真的會 delay 一個 cycle,那為什麼我不把這段也改成 always_comb 讓它沒延遲?
答案是我改過,然後 yosys 就不用 block memory 來實現 ram 了,而是直接把 16K 的 memory,改成用另一個元件 TRELLIS_SLICE 打散來實現,
但這樣立刻就會超過 icesugar-pro 的使用上限,因此只能讓 gpu data 延遲一個 cycle。
而因為 gpu data 延遲一個 cycle,在 gpu 裡面也要對應調整,在決定 output 的時候,要用上一個 cycle 的 index 來取,這樣才不會破圖:
logic [3:0] index;
assign index = counterX[3:0] - 1;
always_comb begin
if (counterX >= 512 || counterY >= 256) begin
o_pixel = 24'd0;
end
else begin
o_pixel = (i_data[index]) ? 24'hffffff : 0;
end
end
有了這兩個補丁之後,nand2tetris 裡面的範例就可以正常執行了,執行結果如下:

完全執行要 40 秒左右,換算執行了大約 1G 個指令…,沒辦法這個 CPU 就是極簡,沒有太多指令可用, 然後我的編譯器也沒有最佳化,寫一個 pixel 可能就要上百條指令才會完成。
結語
經過 nand2tetris 範例的測試, CPU 運作應該是沒有問題了,除了 assembler 之後,其他編譯器跟 VM translator 都沒找到問題。 雖然是個很簡單的 CPU,但這也是第一次在 FPGA 上實作一顆 CPU 出來,也是滿有成就感的;Nand2Tetris 的鍵盤目前還沒實作, 這部分有一些考量點,應該留到下一篇再來討論。
現在的系統還有 block memory 的限制,因為 Nand2Tetris CPU 能做的事非常簡單,再簡單的運算都要用掉一卡車的指令, 導致 Nand2Tetris 的 code 比我想像的還要肥一點,把整套 OS service 都編進去,幾乎所有範例都會超過我們 24K 的容量上限, 更別提在上面寫 Tetris 了。
當然這個問題,可以列出幾個解法:
- 讓 yosys 支援 dual port memory,這樣 display 就不用用到兩倍只要 8K 就夠,但以 issue 卡關的程度來看,應該不是短期能辦到的事。
- 設法接通 DRAM,這樣 block memory 56K 全部拿來當 ROM,但這個也是有點難度。
Xilinx 課金下去就對了,課金治百病
總之,我們這章已經在概念上驗證用 FPGA 實作 Nand2Tetris CPU 的可能性,下一步就來實作鍵盤的介面了。