故事是這樣子的, 很早以前我寫過一篇介紹 python ctypes 的文章,已經是 7 年前的文章了, 大約在去年左右,曾經發現一個生猛的用法但那時沒記下來,最近又用到了結果又要花時間找設定,這篇就再次記錄一下。
一個 C 的函式通常是這樣子的,首先會先寫好 header 標頭跟 c 實作,整體編成 library 檔之後,
最後跟 c 的 main 函式進行連結變成執行檔,這個執行檔可能是測試也可能是實際產品的主程式。
但想必寫過的人都知道,作為底層而低階的 C 語言,沒有如 C++ 等易用的函式庫,使用起來非常不方便,特別是當你習慣如 C++
甚至 python 的資料處理方式之後,回頭去寫 C 只會讓你加倍痛苦。
那麼就如上一篇文中所說,我們可以用 Python ctypes 來處理和 C 的介接,以下就用 tiny AES
當個範例,來看一下這個方法能做到什麼程度。
tiny-AES-c 是個極簡的 library,連 AES padding 的功能都沒有,一切都要我們自己處理,但這樣更好,反而更能突顯用 python 嫁接的優勢。
準備 .so
要用這個方法,一步就是準備 .so 檔。
Python ctypes 只吃 shared library,因此在 CMakeLists.txt 中要將 add_library 加上 SHARED,讓它生出 shared library;
Makefile 的話就比較麻煩,要自行加上 aes.so 這個編譯目標,並使用 LINK.cc 幫你把 .o 連接成 .so。
要注意的是 ctypes 要吃的 .so 必須沒有任何 dependency (至少沒簡單的方式可以繞過),例如 func.o,裡面會用到 depend.o,
在 CMake 編譯 .so 的時候,target_link_libraries 就要把 depend.o 加進去,
否則 python ctypes.CDLL 底層呼叫的 dlopen 會出現 OSError: undefined symbol。
用 Python 連接 C 函式
以下是我寫的 aes.py,用來進行 AES ECB 跟 CBC 的加密,開頭自然是用 ctypes 的 CDLL 將編譯出來的 libtiny-aes.so 引入。
from ctypes import *
import os
# Load the shared library
lib_path = os.path.abspath("build/libtiny-aes.so")
lib = CDLL(lib_path)
觀察 aes.h 的定義,AES_ctx 為:
struct AES_ctx
{
uint8_t RoundKey[AES_keyExpSize];
#if (defined(CBC) && (CBC == 1)) || (defined(CTR) && (CTR == 1))
uint8_t Iv[AES_BLOCKLEN];
#endif
};
就是兩個 uint8_t 的陣列,因此我們可以直接轉譯成 python ctypes,AES_keyExpSize = 176, AES_BLOCKLEN = 16 這種常數必須自己寫好,它們在編譯期就決定了:
class Ctx(Structure):
_fields_ = [("RoundKey", c_byte * 176), ("iv", c_byte * 16)]
ctx = Ctx()
下面就是初始化 key 跟要加密的內文了,基本上 pointer 都能從 python 的 bytes 直接呼叫,相當方便。
答案都跟 cyberchef
上生成的答案相同,大家可以自行驗證。
# Prepare the input buffer
key = bytes.fromhex("2b7e151628aed2a6abf7158809cf4f3c")
buf = bytes.fromhex("6bc1bee22e409f96e93d7e117393172a")
# ECB demo
lib.AES_init_ctx(ctx.RoundKey, key)
lib.AES_ECB_encrypt(ctx.RoundKey, buf)
assert buf.hex() == "3ad77bb40d7a3660a89ecaf32466ef97"
# CBC demo
key = bytes.fromhex("2b7e151628aed2a6abf7158809cf4f3c")
buf = bytes.fromhex("6bc1bee22e409f96e93d7e117393172a")
iv = bytes.fromhex("000102030405060708090a0b0c0d0e0f")
lib.AES_init_ctx_iv(byref(ctx), key, iv)
lib.AES_CBC_encrypt_buffer(byref(ctx), buf, 16)
assert buf.hex() == "7649abac8119b246cee98e9b12e9197d"
我們可以寫什麼
光看上例,光是能用 bytes.fromhex 來初始化一個 buffer,就已經比 c uint8_t[] 再自幹函式從 hex string 去初始化強上不少。
又如我們想要處理 CBC 的 padding,必須在不滿 16 bytes 的 data 後面,用需要 padding 的數字補到 16 bytes,這在 python 內也是簡單就可以做到:
buf = bytes.fromhex("6bc1bee22e409f96")
padsize = 16 - len(buf) % 16
padding = bytes([padsize] * (padsize))
buf += padding
print(buf.hex())
這一切都比寫 C 來得強,Python 自動管理記憶體也不容易在準備資料時就出現記憶體相關的錯誤,拖慢開發速度。
從 Python debug
其實如果只是用 ctypes call C 函式那也就算了,這也是個成熟的做法了。
但最殺手級的是,由於 C library 的 debug 資訊是包含在 .so 裡面的(所以整個連結成 main 的時候 gdb 才有能力去 debug),
dlopen 同樣會將這些除錯資訊載入,因此我們可以用 gdb 除錯 python 執行檔,執行我們的介面 py 程式,設在 .c 檔內的中斷點還是可以運作。
初見這招的時候真的覺得超級猛,用命令列來說的話大概是這樣:
gdb /usr/bin/python
b AES_ECB_encrypt
r aes.py
在打中斷點的時候 gdb 會顯示符號不存在,這很自然因為 .so 檔還沒載入。
Function "AES_ECB_encrypt" not defined.
Make breakpoint pending on future shared library load? (y or [n]) y
如果是使用 vscode,可以選左側的 Run and Debug,在 launch.json 的 configuration 中加入下列內容:
{
"name": "(gdb) Launch",
"type": "cppdbg",
"request": "launch",
"program": "/usr/bin/python",
"args": [
"aes.py"
],
"stopAtEntry": false,
"cwd": "${fileDirname}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "Set Disassembly Flavor to Intel",
"text": "-gdb-set disassembly-flavor intel",
"ignoreFailures": true
}
]
},
{
如下圖所示,透過 python 呼叫 C 函式,並在進入 C 函式是進入中斷除錯。
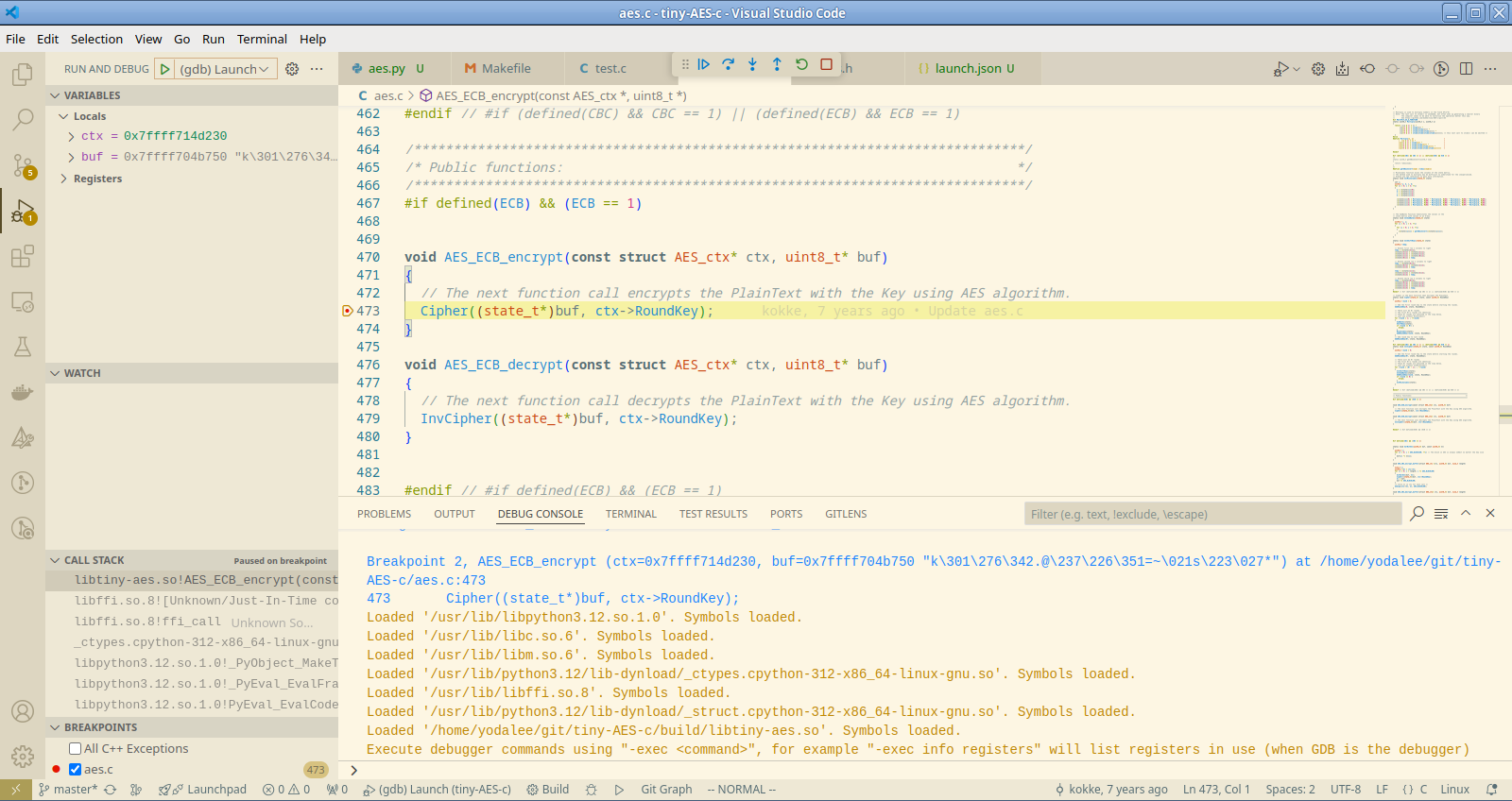
結語
總之這篇記錄了,怎麼用 python 呼叫 C 函式庫,並使用 gdb, vscode 等除錯工具進行除錯。
就我個人而言,這個作法的好處在於上面提到的,一是 python 就資料處理相比 C 豐富得多,很多地方不用重造輪子(雖然現在輪子給 AI 就能造,
人類只需要複製貼上);二是 python 的測試框架還是比 C 完整與易用,把函式庫的介面訂好,可以搭配 python unittest 完成 C 函式的測試。
缺點當然也顯而易見,Python ctypes 畢竟不是 C,如果用到較複雜的資料型態,或者是受編譯選項影響的資料型態,也許 ctypes 就沒法勝任了。
如果 C 函式庫還在開發中則資料型態可能還會演進,若是純 C 則編譯器會幫你進行檢查,但 Python 就不會有任何檢查與提醒,只會看到函式呼叫下去整個壞掉卻也不知道為什麼。
總之這個作法各有利弊,要不要用就請大家自行判斷了。