在上一篇我們看到如何連接 AHB bus 之後,這篇我們來看看 AXI stream。
如果有看過 AXI Lite 介面的使用方式,它是幫你把 AXI 的讀寫轉化成內部的
registers,而每次的讀寫都是超級花費時間的事情,如果有大量的資料需要讀寫,用 AXI Lite
並在讀寫空間開幾百個 registers 就很不適合,太浪費時間,沒辦法有效率的把資料送進 IP,或從 IP 讀出來。
AXI stream 介面
AXI stream 就是針對這點而生,AXI stream 的介面上只留下以下幾個埠:
- valid
- ready
- data
- last
- (optional) strobe
- (optional) keep
每次的 valid/ready 交握就會傳輸一次資料,last assert 表示這筆交握是最後一筆資料,strobe 與 keep 則是用來表示資料中個別的位元的有效性,在 32 bits 的 AXI stream bus 上,strobe, keep 兩個埠都是 4 bits;64 bits bus 則是 8 bits。
有關 AXI stream strobe 與 keep 的搭配的簡單統整:
| Strobe = 1 | Keep = 1 | Data |
| Strobe = 1 | Keep = 0 | Don't use |
| Strobe = 0 | Keep = 1 | Position |
| Strobe = 0 | Keep = 0 | Null |
所謂的 Position bytes,指的是類似傳輸圖片或大筆資料,可以在其中插入一些檢查碼,例如 Hamming
code;或者現在傳輸在整批資料中的位置,像是傳輸開頭的 position 會以 00 表示,諸如此類。
相關的參考資料,可以先看參考 带你快速入门AXI4总线--AXI4-Stream篇
或是直接啃 ARM 的規格書 AMBA 4 AXI4-Stream Protocol Specification
。
與 PS side 的 DMA 模組搭配,就能用全速讀寫記憶體,這篇我們就來看看,要怎麼實作一個接收
AXI stream 的模組,從記憶體灌大量的資料給模組。
這篇的主參考(其實接近翻譯)來自於下面這兩篇文章:
建立 IP
測試用的模組
我們這輪先實作一個單向,只有 stream 寫入的模組,為了讓 keep 有用,實作模組的規格如下:
輸入的資料,每個 bytes 會先反轉,再把每個 bytes 加起來,輸出加總的結果。
同樣我們請 AI 幫我們實作(這次的 prompt 不太好下,而且 AI 最後用了一堆 function 還不管 axi keep 我有再小修):
Input 32 bits AXI stream
Output 8 bits o_data
The module should flip each valid byte transferred, and sum the result to o_data
Keep the output until next DMA transfer
module StreamAdder (
input logic aclk,
input logic aresetn,
// AXI-Stream slave
input logic [31:0] s_axis_tdata,
input logic s_axis_tvalid,
output logic s_axis_tready,
input logic [3:0] s_axis_tkeep,
input logic s_axis_tlast,
// Output
output logic [7:0] o_data
);
logic [7:0] acc;
logic in_packet;
// Always ready (no backpressure)
assign s_axis_tready = 1'b1;
always_ff @(posedge aclk or negedge aresetn) begin
if (!aresetn) begin
acc <= 8'd0;
o_data <= 8'd0;
in_packet <= 1'b0;
end else begin
if (s_axis_tvalid && s_axis_tready) begin
// Start of new packet (after previous TLAST)
if (!in_packet) begin
in_packet <= 1'b1;
acc <= 8'd0;
end
// Accumulate (truncate to 8-bit)
acc <= acc +
(s_axis_tkeep[0] ? s_axis_tdata[0 +:8] : 8'b0) +
(s_axis_tkeep[1] ? s_axis_tdata[8 +:8] : 8'b0) +
(s_axis_tkeep[2] ? s_axis_tdata[16+:8] : 8'b0) +
(s_axis_tkeep[3] ? s_axis_tdata[24+:8] : 8'b0);
// End of packet
if (s_axis_tlast) begin
o_data <= acc +
(s_axis_tkeep[0] ? s_axis_tdata[0 +:8] : 8'b0) +
(s_axis_tkeep[1] ? s_axis_tdata[8 +:8] : 8'b0) +
(s_axis_tkeep[2] ? s_axis_tdata[16+:8] : 8'b0) +
(s_axis_tkeep[3] ? s_axis_tdata[24+:8] : 8'b0);
in_packet <= 1'b0;
end
end
end
end
endmodule
存檔成為 StreamAdder.sv
打包 IP
在 Vivado ,建立一個新的 IP:
- Tools -> Create and Package New IP
- 選擇 Create a new AXI4 Peripheral,模組命名為 StreamAdder
- 在 AXI 的介面上,新增一個 AXI stream interface
- 介面設定為 Slave
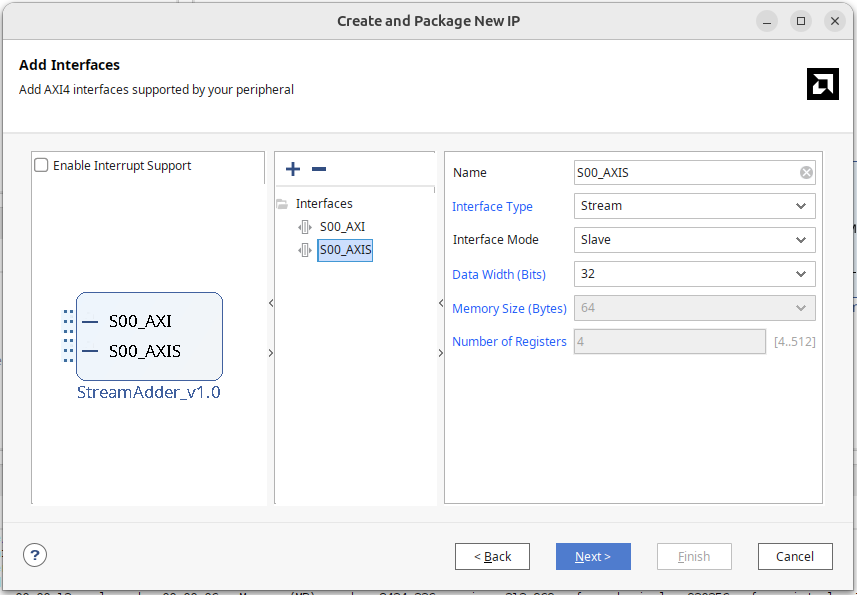
新建的模組會看到一個 S00_AXIS 的模組,Vivado 在 AXI Lite 會生成一個承接 AXI Lite
信號的模組,並能夠讀寫其中的暫存器;同樣的 AXIS 模組能夠承接 AXI Slave stream
的信號,並寫入其中的 FIFO 記憶體。
當然我們可以在 AXIS 模組中新增從 FIFO 記憶體中把資料再讀出的邏輯,但我們的模組本身就能接收
AXI stream 了,就把這個 StreamAdder_v1_0_S00_AXIS 的程式碼和實例刪掉。
預設的模組接線如下圖上,我們會把它改成下圖下:
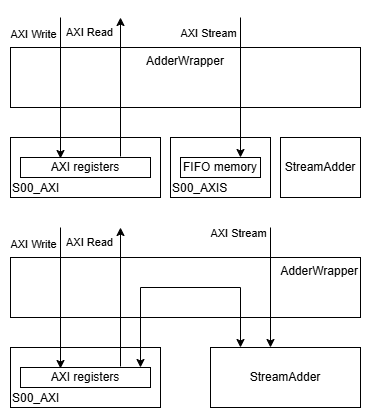
AXI stream 帶的介面如下:
- s00_axis_tvalid
- s00_axis_tready
- s00_axis_tdata
- s00_axis_tlast
- s00_axis_tstrb
把線接入我們模組中即可。
如果不想用 Vivado 自行產生的,也可以像上一篇 AHB 一樣自行打包 IP,選擇 axis 就可以了。
Block Diagram
與之前相同,建立一個 Pynq-Z2 專案,在 block diagram 中設定好 Pynq7000 處理器與及我們的 IP。
控制 DMA 使用的是 AXI Direct Memory Access 這個 IP block,可以將模組名稱修改為 dma,就像
AXI Lite 一樣,Python 會用這個名字來控制 DMA 模組。
DMA 模組介面
我們來解構一下 DMA 這個模組,從介面上可以看到
S_AXI_LITE
AXI Slave 控制埠,用來設定 DMA、啟動/停止 DMA、讀取狀態。
平常會被包裹在 pynq 抽象化過後的 python module 之後,不會直接碰到。
AXI Stream
DMA 有兩個 Stream 埠:
- M_AXIS_MM2S 首字的 M 表示 Master,即發動將記憶體資料寫入 AXI stream 模組
- S_AXIS_S2MM 由 stream 模組接收資料
Stream 埠與 IP 的溝通是可以被卡住的,如果你的 IP input 不拉 i_ready 或是 output 不拉 o_valid,那麼都有可能導致 DMA 模組卡死。
AXI Master
DMA 有兩個 AXI Master 埠,接至 Zynq 的 HP (High-Performance) AXI Slave 埠以存取記憶體,這兩個埠都是 AXI full 的實作:
- M_AXI_MM2S,從(PS DRAM)讀取資料送入 AXI-Stream 模組。
- M_AXI_S2MM,接收模組來的 AXI-Stream 資料,寫回記憶體。
- M_AXI_SG,SG 是指 Scatter Gather,可以從多個不連續的地方存取記憶體。
在 PYNQ 映像中這些 HP 埠通常預設為 64-bit 寬,其中的 MM 意思是 Memory-Mapped。
在 python 端的 driver 並不支援 scatter gatter,只支援來自連續記憶體的 DMA
傳輸;如果要用 scatter gather 的話就要使用 M_AXI_SG port,這邊我們先略過不提,等末來
進階改用 C programming 寫 driver 的時候再來介紹。
設定 DMA 參數
在 Vivado 裡點兩下開啟 DMA 設定:
- 取消勾選 “Enable Scatter Gather Engine”。
- 設定 Buffer Length Register,依使用量設定 Buffer Length Register 的寬度,設成最大為
26 bits,則單次可搬運 64 MB 的資料。
這個欄位的預設值只有 14 bits,也就是 16 KB 的資料,如果你傳送的 buffer 尺寸超過上限,內部收到的資料就會被截斷;超過的尺寸可以發起多次 DMA 來解決。 - 設定 Address Width 為 32 bits。
若使用 Zynq UltraScale+ 並且 memory address 寬度更大,可設定為 64 bits。 - 因為我們這次要把記憶體的資料讀進 IP,所以只勾選 Read channel,取消勾選的時候會看到 write 相關的 channel: M_AXI_S2MM、S_AXIS_S2MM 就不見了。
Memory-mapped data width 和 stream data width 用 32 bits,雖然 32 bits 與 Zynq7000 HP port 的寬度不一致,但這沒關係,就算寬度一樣了 DMA 的 M_AXI 通道跟下面處理器的 HP 通道仍然無法直接相連,要在中間插入 AXI Interconnect 作為中介調和信號介面。
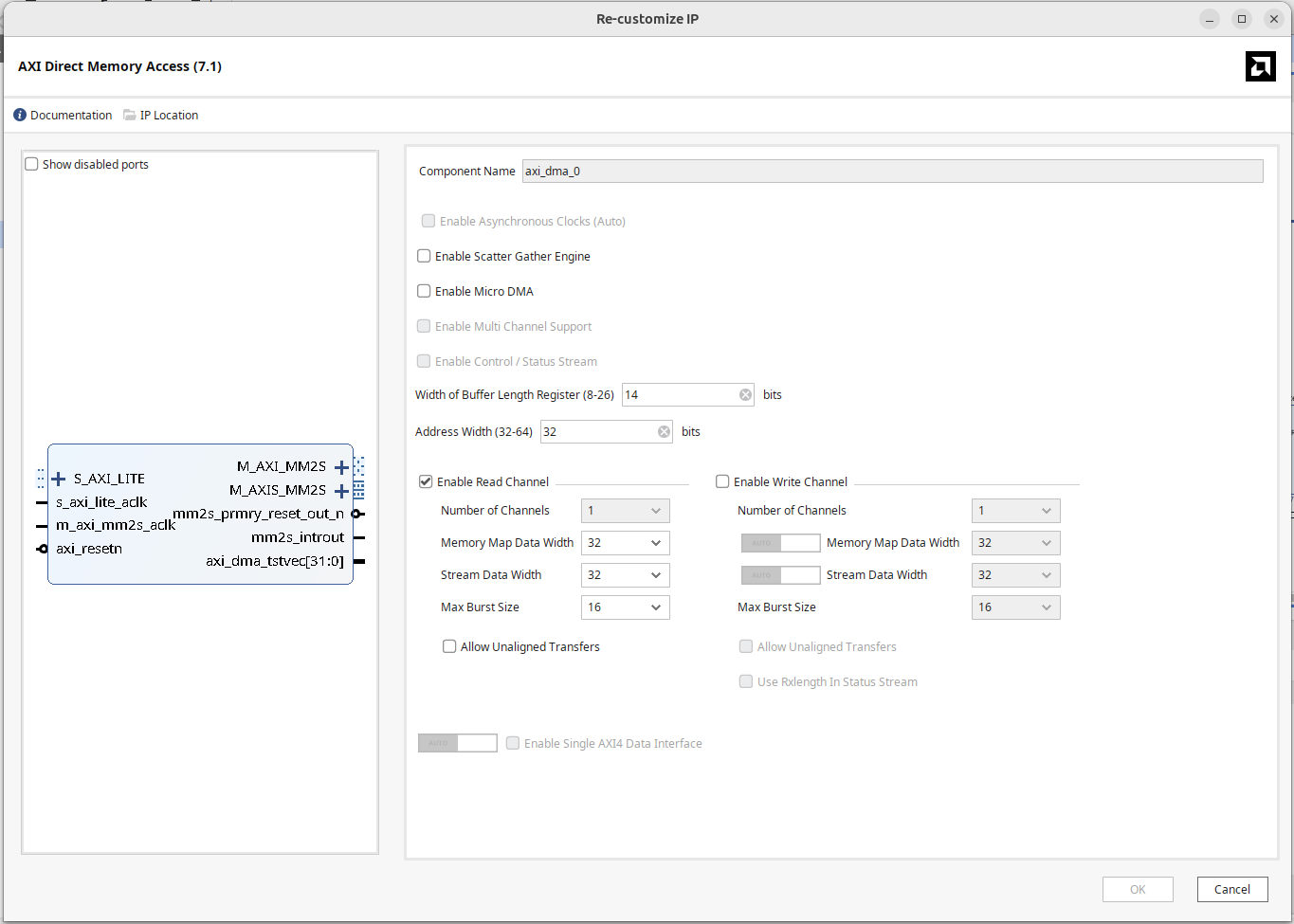
DMA 主記憶體埠連線
要讓 DMA 的 Master 埠存取 DRAM:
在 Zynq 內部,四個 HP Port 實際上是透過兩組記憶體交換器(switch)連到 PS Memory:
- HP0 與 HP1 共用同一組 switch
- HP2 與 HP3 共用另一組 switch
若設計只需要使用兩個 HP Port,通常會建議選擇「不共用 switch」的組合,以獲得較佳的效能, 例如:HP0 搭配 HP2 會比 HP0 搭配 HP1 更有效率。
Zynq 處理器預設不會打開 high performance port,在處理器的設定中:
- 在 PS/PL Configuration, HP Slave AXI Interface 裡啟用 S AXI HP0 / S AXI HP2。
- 設定 HP 埠的位寬為 64 bits。
這個 64 bits 的寬度是在 Pynq 開機時設定好的,Pynq 預設的映像檔設定是 64
bits,因此這裡必須要設 64 就好。
若不小心設定成 32-bit,實際只會正確傳輸一半資料,這個症頭的描述是在做 DMA
傳輸時,每 64 bits 的資料傳輸都會掉 32 bits。
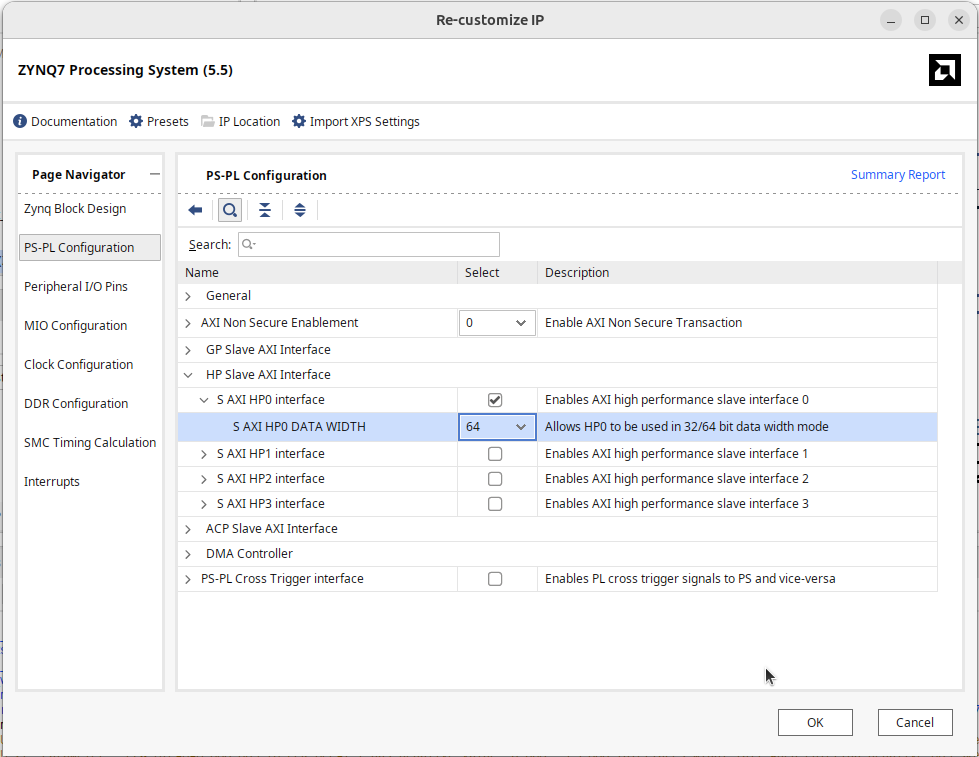
出現 S_AXI_HP0 和之後,透過 AXI interconnect ,將 DMA 模組的 M_AXI_MM2S 和連接到 S_AXI_HP0。 最後把 DMA 的 M_AXIS_MM2S 連接到我們 IP 的 S_AXIS 上。
完成設計
完成的 block diagram 如下圖所示:
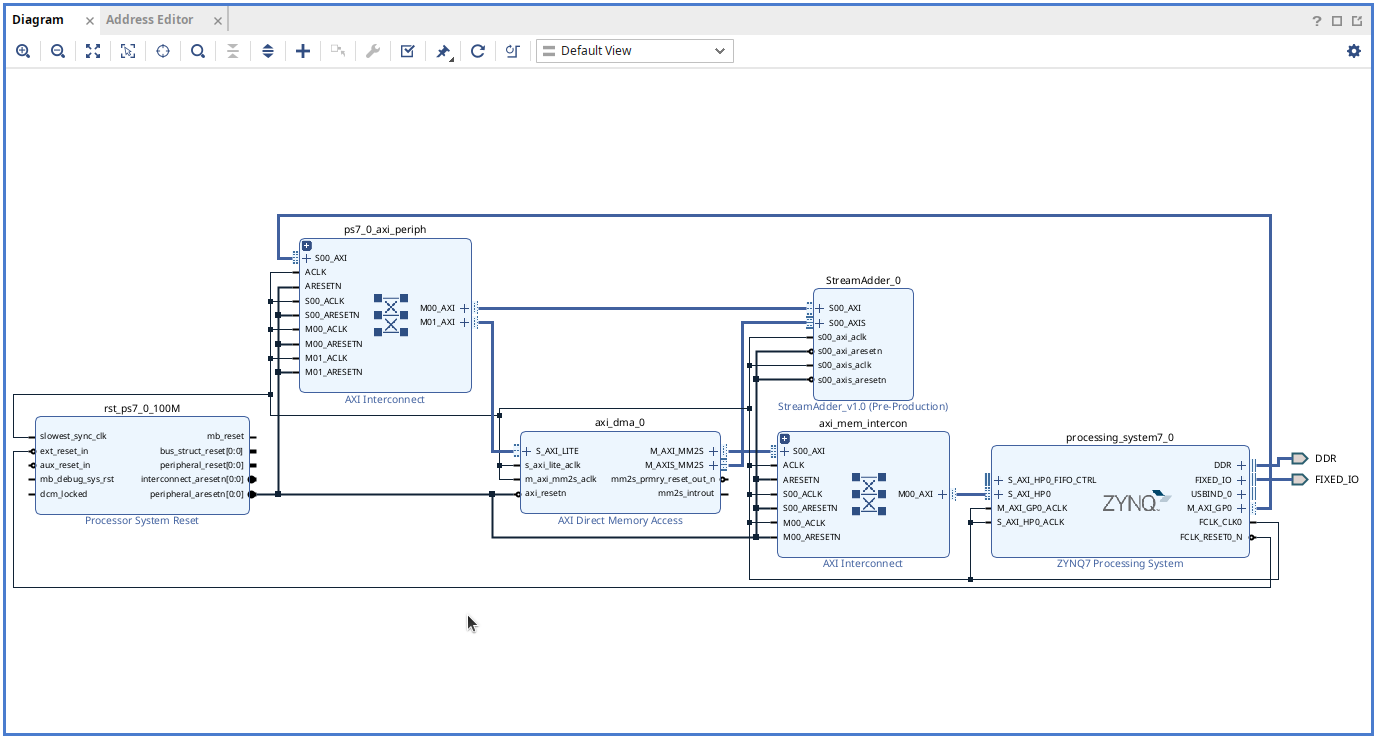
按 F6 進行設計驗證,確保沒有錯誤。
產生 HDL wrapper 與 bitstream。
將產生的 .bit 與 .hwh 放到 PYNQ 板子上的資料夾。
Pynq 測試程式
from pynq import Overlay, allocate
ol = Overlay("ReadDMA.bit")
在載入 Overlay 之後,可以用 ? 看到內部的資料:
ol?
IP Blocks
----------
axi_dma_0 : pynq.lib.dma.DMA
StreamAdder_0 : pynq.overlay.DefaultIP
processing_system7_0 : pynq.overlay.DefaultIP
如上所示,會看到 DMA 控制器 axi_dma_0 和 AXI Lite 上的 StreamAdder_0 IP block。
DMA 控制器可以取用寫資料給 IP 的 sendchannel 與讀取資料的 recvchannel
,後者這裡還不需要。
dma = ol.axi_dma_0
ip = ol.StreamAdder_0
dma_send = dma.sendchannel
Read DMA
要進行 DMA 讀取,首先要先分配一塊記憶體給 DMA。
pynq 中提供了 allocate 函式,搭配 numpy 的資料型態進行記憶體分配,這裡我們求簡單只分配 64
bits;用 transfer 將資料透過 DMA 模組往 IP 送。
input_buffer = allocate(shape=(2,), dtype=np.uint32)
input_buffer[0] = 0x00000000
input_buffer[1] = 0x00000000
dma_send.transfer(input_buffer)
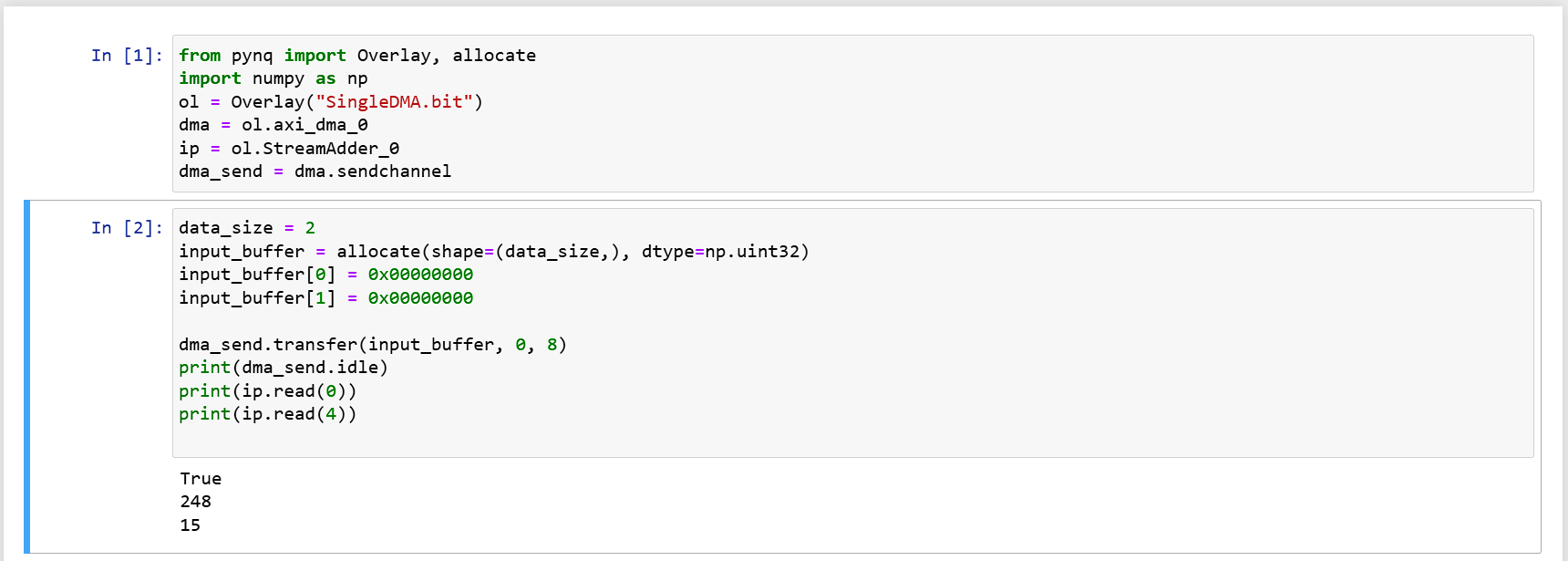
就會得到 248 = -8 這個答案了
因為範例只有 transfer,後來我去找了 pynq dma 的原始碼,才找到它的參數,以下的實作就能指定只傳送 6 個 bytes 進去,前面的 1010 不會被硬體吃到,所以輸出 250 = -6。
input_buffer = allocate(shape=(2,), dtype=np.uint32)
input_buffer[0] = 0x00000000
input_buffer[1] = 0x10100000
dma_send.transfer(input_buffer, start=0, length=6)
print(ip.read(0))
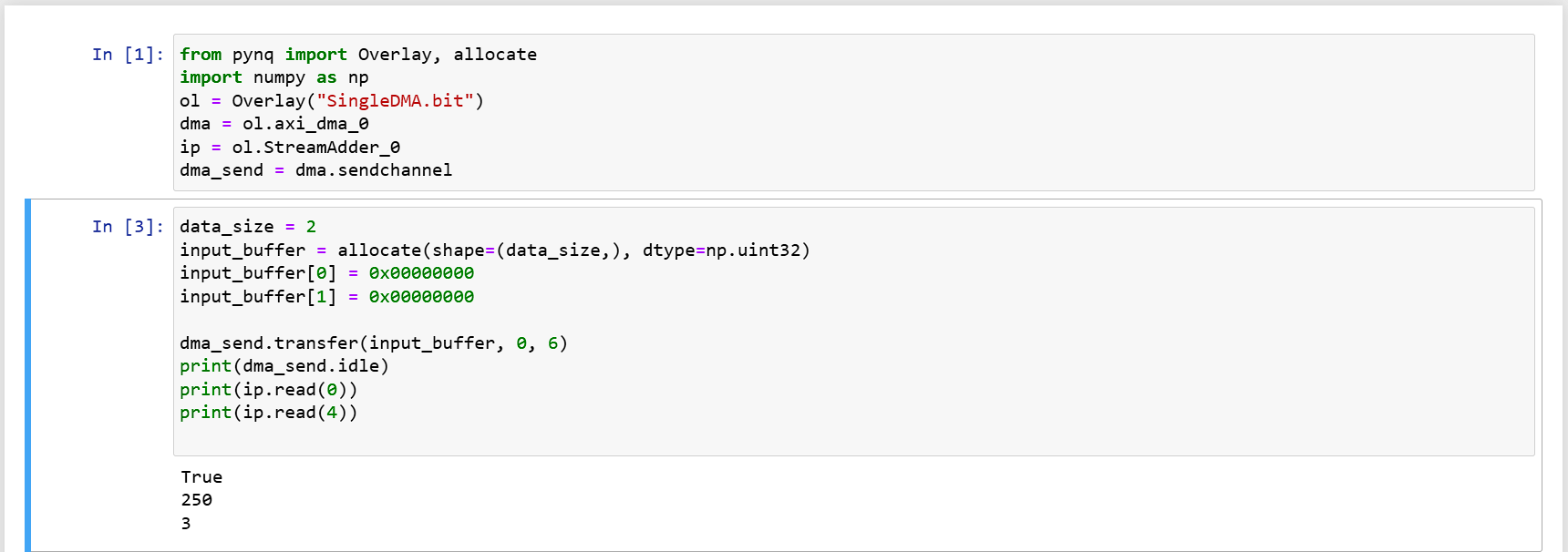
Keep 的問題
如果你都照著我上面的步驟做的話,會發現第二個例子的結果是錯的,原因來自於
AXI stream 的 keep 接線。
預設的 AXI Stream 介面是沒有 KEEP 埠的,所以 vivado 並不會把 DMA 模組的 keep
線接給我們的模組,但這個問題就算你把 AXI Stream 展開也看不出來,Vivado
並不會顯示個別埠的連線狀況,我覺得這點超級煩…如果我都點開了你就顯示一下連線狀況嘛。
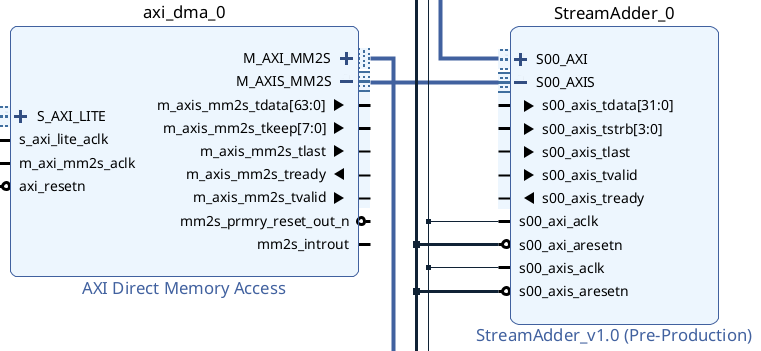
生成程式碼的時候,Vivado 會很天才的自動連接 4 個 bits 的 1,也就是每個 bytes 都吃。
這個問題非常隱微,第一次嘗試最後動用 ila core 搭配除錯線,發現 IP 端 KEEP
怎麼一直收到全 1,點開生成的頂層程式碼觀察接線才抓到。
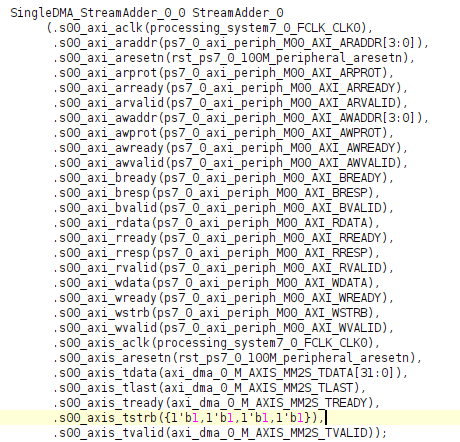
要修正這個問題,我們要回到 IP 中,把本來提供的 tstrb 埠複製一份,改名為 tkeep。
在 Port and Interface,將新加入的 tkeep 映射到 AXI Keep。
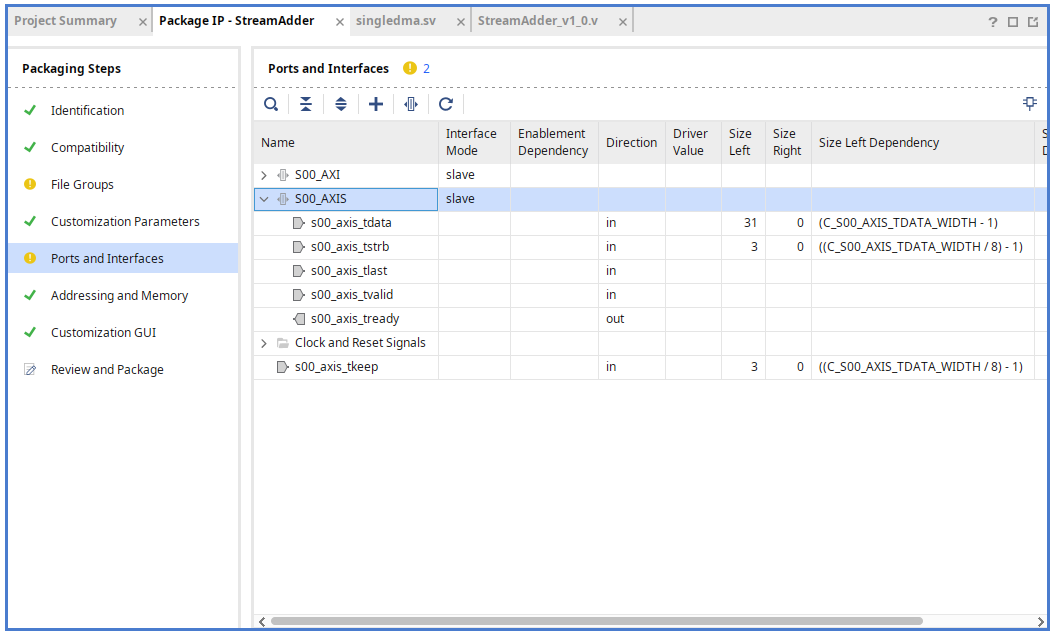
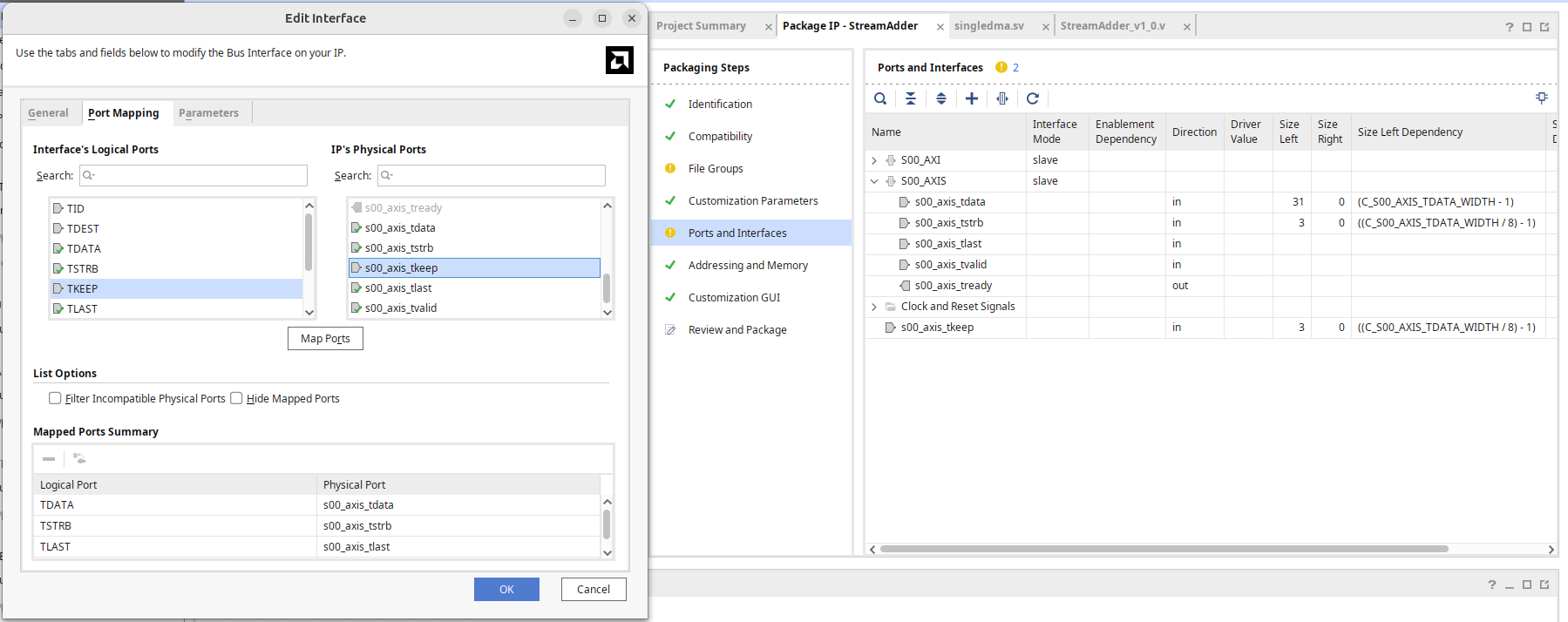
這樣重新打包之後就完成了。
另外值得一提的是 pynq 的 DMA driver 會是靠 LSB 放的(其實想想也合裡,照記憶體位址來看就是低到高),送資料時 keep 值會是 1, 3, 7, F。
至於能不能發起一個長度為 0 的 DMA transfer,至少看原始碼在 python driver 層會直接把長度設定為輸入 buffer 的長度,實務上只要長度是 0,直接不發 DMA 就好了。
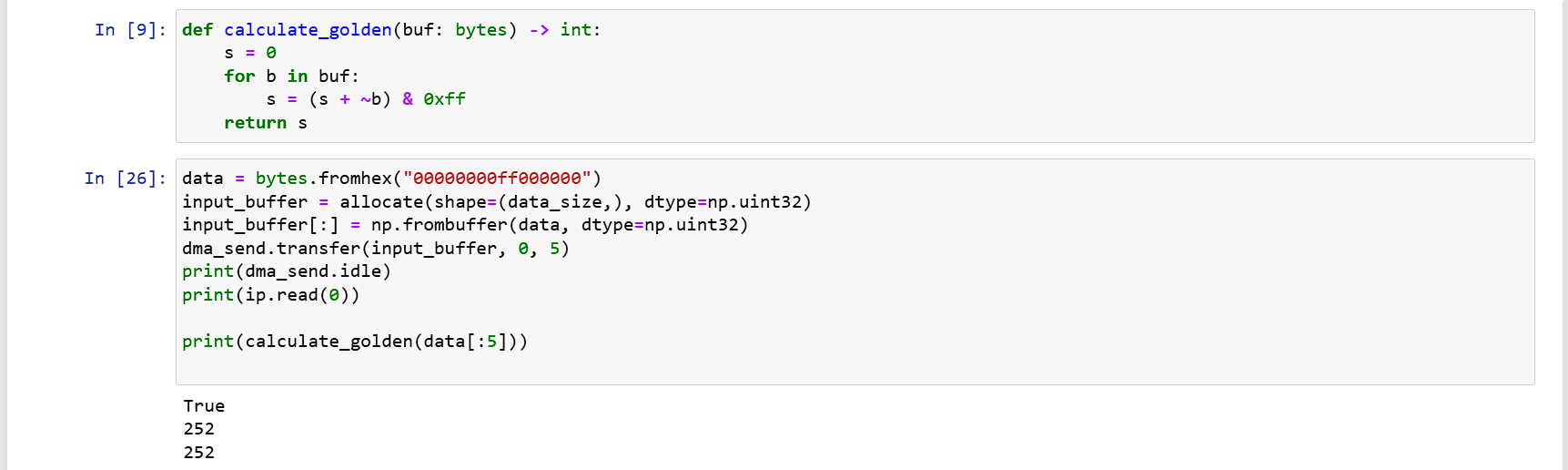
高效的寫法
上述的 allocate 會回傳一個 ndarray 的延伸,可以存取 physical address,但不是純粹的 numpy ndarray。
在 driver 需要傳送一個使用者丟來的 bytes 物件,又不想要一直 call allocate 函式,參考討論區的寫法如下:
# in constructor
buffer = allocate(shape=(BUF_SIZE,), dtype=np.uint32)
# in driver function
def send_data(data: bytes):
buffer[:] = np.frombuffer(data, dtype=np.uint32)
dma.transfer(buffer)
結論
這篇我們展示怎麼在 Xilinx FPGA 上連接 DMA,並寫一個簡單的模組來驗證 DMA 讀取真的有運作,下一篇我們就來看看寫入的 DMA 該怎麼做。